
Why Deep Learning Matters in Modern AI Systems
A Cross-Vendor Training Guide
Certification Alignment: NVIDIA DLI, TensorFlow Developer, AWS ML Specialty, Azure AI-102, Azure AI-900, CompTIA AI+
Introduction
Deep learning is a subset of machine learning that uses artificial neural networks with multiple layers to learn hierarchical representations of data. These “deep” networks have revolutionized AI, achieving superhuman performance in image recognition, natural language processing, and game playing.
What Is Deep Learning?
Deep learning uses neural networks with many layers (hence “deep”) to automatically learn features from raw data. Unlike traditional ML where engineers manually design features, deep learning learns optimal feature representations directly from data.
Deep Learning vs. Traditional Machine Learning
| Aspect | Traditional ML | Deep Learning |
| Feature Engineering | Manual, requires domain expertise | Automatic, learns from data |
| Data Requirements | Works with smaller datasets | Requires large datasets |
| Compute Requirements | CPU sufficient | GPU/TPU often required |
| Interpretability | Often interpretable | Often “black box” |
| Performance Ceiling | Limited by feature quality | Scales with data and compute |
When to Use Deep Learning
Deep learning excels when:
- You have large amounts of labeled data (millions of examples)
- The problem involves unstructured data (images, text, audio)
- Features are difficult to engineer manually
- You have access to GPU compute resources
- State-of-the-art accuracy is required
The Biological Inspiration
Neural networks are inspired by biological neurons in the brain, though artificial neurons are highly simplified.
Biological Neuron
Dendrites (inputs) → Cell Body (processing) → Axon (output) → Synapses (connections)
A biological neuron receives signals through dendrites, processes signals in the cell body, fires (or not) based on accumulated signals, and transmits signal through the axon to other neurons.
Artificial Neuron (Perceptron)
Inputs (x₁, x₂, …, xₙ) → Weighted Sum → Activation Function → Output
Mathematical Representation:
output = activation(Σ(wᵢ × xᵢ) + bias)
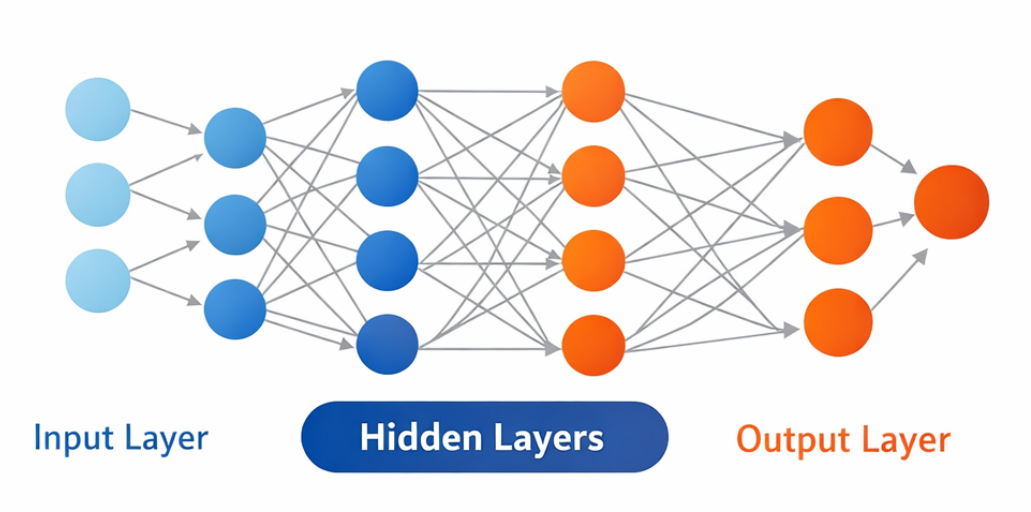
Neural Network Architecture
Layers
1. Input Layer
- Receives raw data (pixels, words, numbers)
- Number of neurons = number of input features
- No computation, just passes data forward
2. Hidden Layers
- Perform transformations on data
- Learn increasingly abstract features
- “Deep” networks have many hidden layers
3. Output Layer
- Produces final predictions
- Binary classification: 1 neuron with sigmoid
- Multi-class classification: N neurons with softmax
- Regression: 1 neuron with linear activation
Vendor References:
| Vendor | Documentation |
| NVIDIA | developer.nvidia.com/discover/neural-network |
| developers.google.com/machine-learning/crash-course/introduction-to-neural-networks | |
| Microsoft | learn.microsoft.com/azure/machine-learning/concept-deep-learning-vs-machine-learning |
Activation Functions
Activation functions introduce non-linearity, enabling neural networks to learn complex patterns. Without activation functions, a deep network would be equivalent to a single linear transformation.
Common Activation Functions
1. Sigmoid
σ(x) = 1 / (1 + e^(-x))
- Output range: (0, 1)
- Use case: Binary classification output, gates in LSTMs
- Problem: Vanishing gradients for extreme values
2. Tanh (Hyperbolic Tangent)
tanh(x) = (e^x – e^(-x)) / (e^x + e^(-x))
- Output range: (-1, 1)
- Use case: Hidden layers (older architectures), RNNs
- Advantage: Zero-centered output
3. ReLU (Rectified Linear Unit)
ReLU(x) = max(0, x)
- Output range: [0, ∞)
- Use case: Hidden layers in most modern networks
- Advantages: Fast computation, reduces vanishing gradient
- Problem: “Dying ReLU” – neurons can become permanently inactive
4. Leaky ReLU
LeakyReLU(x) = x if x > 0, else αx (typically α = 0.01)
- Solves the dying ReLU problem
5. Softmax
softmax(xᵢ) = e^(xᵢ) / Σⱼ e^(xⱼ)
- Output range: (0, 1), sums to 1
- Use case: Multi-class classification output layer
- Produces probability distribution over classes
Choosing Activation Functions
| Layer Type | Recommended | Reason |
| Hidden layers (default) | ReLU | Fast, effective, standard |
| Hidden layers (deep) | Leaky ReLU or ELU | Prevents dying neurons |
| Binary classification output | Sigmoid | Outputs probability |
| Multi-class output | Softmax | Probability distribution |
| Regression output | Linear (none) | Unbounded output |
Loss Functions
Loss functions measure how wrong the model’s predictions are. The goal of training is to minimize the loss.
Common Loss Functions
1. Mean Squared Error (MSE) – Regression
MSE = (1/n) × Σ(yᵢ – ŷᵢ)²
- Penalizes large errors heavily
- Sensitive to outliers
2. Binary Cross-Entropy – Binary Classification
BCE = -(1/n) × Σ[yᵢ log(ŷᵢ) + (1-yᵢ) log(1-ŷᵢ)]
- Standard for binary classification
- Works with sigmoid output
3. Categorical Cross-Entropy – Multi-class Classification
CCE = -(1/n) × ΣᵢΣⱼ yᵢⱼ log(ŷᵢⱼ)
- Standard for multi-class problems
- Works with softmax output
Choosing Loss Functions
| Task | Loss Function | Output Activation |
| Regression | MSE or MAE | Linear |
| Binary Classification | Binary Cross-Entropy | Sigmoid |
| Multi-class (one-hot) | Categorical Cross-Entropy | Softmax |
| Multi-class (integer) | Sparse Categorical CE | Softmax |
| Multi-label | Binary Cross-Entropy | Sigmoid (per class) |
Backpropagation
Backpropagation is the algorithm for computing gradients of the loss with respect to each weight, enabling the network to learn.
The Chain Rule
Backpropagation applies the chain rule of calculus to compute gradients layer by layer, moving backward from output to input.
The Vanishing Gradient Problem
In deep networks, gradients can become extremely small as they propagate backward, causing early layers to learn very slowly.
Causes:
- Sigmoid/tanh activations saturate (derivatives near 0)
- Many multiplications of small numbers
Solutions:
- Use ReLU activation (derivative = 1 for positive values)
- Batch normalization
- Residual connections (skip connections)
- Proper weight initialization
Optimization Algorithms
Optimizers update network weights to minimize the loss function.
Gradient Descent Variants
1. Batch Gradient Descent
Computes gradient over entire dataset. Stable but slow.
2. Stochastic Gradient Descent (SGD)
Computes gradient on single sample. Fast but noisy.
3. Mini-Batch Gradient Descent
Computes gradient on batch of samples. Standard approach in deep learning. Typical batch sizes: 32, 64, 128, 256.
Advanced Optimizers
SGD with Momentum
Accumulates velocity in consistent directions. Dampens oscillations. Typical β = 0.9.
Adam (Adaptive Moment Estimation)
Combines momentum and adaptive learning rates. Default choice for most applications. Typical: β₁=0.9, β₂=0.999.
AdamW
Adam with decoupled weight decay. Better generalization. Increasingly popular choice.
Choosing an Optimizer
| Scenario | Recommended Optimizer |
| Default starting point | Adam or AdamW |
| Computer vision | SGD with momentum (often better final accuracy) |
| NLP / Transformers | Adam or AdamW |
| RNNs | RMSprop or Adam |
| Fine-tuning | AdamW with low learning rate |
Regularization Techniques
Regularization prevents overfitting by constraining the model.
1. L1 and L2 Regularization
L2 Regularization (Weight Decay): Loss = Original Loss + λ × Σ(w²)
Penalizes large weights. Encourages smaller, distributed weights. Most common form.
L1 Regularization: Loss = Original Loss + λ × Σ|w|
Encourages sparse weights (many zeros). Feature selection effect.
2. Dropout
During training, randomly set a fraction of neurons to zero.
Benefits:
- Prevents co-adaptation of neurons
- Ensemble-like effect
- Typical dropout rate: 0.2 to 0.5
3. Batch Normalization
Normalize activations within each mini-batch.
Benefits:
- Stabilizes training
- Allows higher learning rates
- Acts as regularization
- Reduces sensitivity to initialization
4. Early Stopping
Stop training when validation loss stops improving. Monitor validation loss and if no improvement for N epochs (patience), stop training and restore best weights.
Common Neural Network Architectures
Feedforward Neural Networks (FNN)
The simplest architecture: information flows in one direction from input to output.
Use Cases: Tabular data classification/regression, simple pattern recognition
Convolutional Neural Networks (CNN)
Specialized for grid-like data (images, sequences).
Key Components:
- Convolutional Layers – Learn local patterns using filters
- Pooling Layers – Reduce spatial dimensions
- Fully Connected Layers – Final classification
Use Cases: Image classification, object detection, medical imaging, video analysis
CNN Vendor References:
| Vendor | Documentation |
| NVIDIA | developer.nvidia.com/discover/convolutional-neural-network |
| tensorflow.org/tutorials/images/cnn | |
| AWS | docs.aws.amazon.com/sagemaker/latest/dg/image-classification.html |
Recurrent Neural Networks (RNN)
Process sequential data by maintaining hidden state.
Variants:
- LSTM (Long Short-Term Memory) – Gates control information flow
- GRU (Gated Recurrent Unit) – Simplified LSTM
Use Cases: Time series forecasting, speech recognition, language modeling
Transformers
Attention-based architecture that processes sequences in parallel.
Key Components:
- Self-Attention – Relate different positions in sequence
- Multi-Head Attention – Multiple attention patterns
- Positional Encoding – Inject sequence order information
- Feed-Forward Layers – Process attention outputs
Use Cases: NLP (BERT, GPT), Computer vision (ViT), Multi-modal AI
Transformer Vendor References:
| Vendor | Documentation |
| tensorflow.org/text/tutorials/transformer | |
| NVIDIA | developer.nvidia.com/blog/understanding-transformer-model-architectures/ |
| Microsoft | learn.microsoft.com/azure/ai-services/openai/concepts/models |
GPU Computing for Deep Learning
Deep learning requires massive parallel computation, making GPUs essential.
Why GPUs?
| Operation | CPU | GPU |
| Matrix multiplication (1000×1000) | ~1 second | ~1 millisecond |
| Training ResNet-50 (1 epoch) | ~hours | ~minutes |
| Parallel operations | 8-64 cores | 1000s of cores |
NVIDIA GPU Ecosystem
Hardware Tiers:
- Consumer (GeForce RTX) – Development, small-scale training
- Professional (RTX A-series) – Enterprise workstations
- Data Center (A100, H100, H200) – Large-scale training
Software Stack:
- CUDA – GPU programming platform
- cuDNN – Deep learning primitives
- TensorRT – Inference optimization
- NCCL – Multi-GPU communication
Cloud GPU Options
| Provider | Service | GPU Options |
| AWS | EC2 P4d, SageMaker | A100, V100, T4 |
| Google Cloud | Compute Engine, Vertex AI | A100, V100, T4, TPU |
| Microsoft Azure | NC-series, Azure ML | A100, V100, T4 |
Deep Learning Frameworks
TensorFlow / Keras
Google’s framework with high-level Keras API.
Documentation: tensorflow.org/learn
PyTorch
Facebook’s framework, popular in research.
Documentation: pytorch.org/docs/stable/index.html
Vendor-Specific Frameworks
| Vendor | Framework | Use Case |
| NVIDIA | NeMo | LLMs, Speech, Vision |
| NVIDIA | RAPIDS | GPU-accelerated data science |
| JAX | Research, high performance | |
| Microsoft | ONNX Runtime | Cross-platform inference |
Key Takeaways
- Deep learning uses neural networks with multiple layers to automatically learn features from data
- Activation functions (ReLU, Sigmoid, Softmax) introduce non-linearity enabling complex pattern learning
- Backpropagation computes gradients using the chain rule, enabling networks to learn
- Adam optimizer is the default choice; SGD with momentum often achieves better final accuracy
- Regularization (Dropout, Batch Norm, Weight Decay) prevents overfitting
- CNNs excel at image tasks; Transformers dominate NLP; RNNs handle sequences
- GPUs are essential for practical deep learning training
- TensorFlow and PyTorch are the dominant frameworks
Additional Learning Resources
Official Documentation
- NVIDIA Deep Learning Institute: nvidia.com/en-us/training/
- TensorFlow Tutorials: tensorflow.org/tutorials
- PyTorch Tutorials: pytorch.org/tutorials/
- Google ML Crash Course: developers.google.com/machine-learning/crash-course
Certification Preparation
- NVIDIA DLI Fundamentals: learn.nvidia.com/courses/course-detail?course_id=course-v1:DLI+C-FX-01+V3
- TensorFlow Developer Certificate: tensorflow.org/certificate
- AWS Deep Learning: aws.amazon.com/training/learn-about/machine-learning/
Article 2 of 5 | AI/ML Foundations Training Series See also AI and Machine Learning Fundamentals
Level: Intermediate | Estimated Reading Time: 30 minutes | Last Updated: February 2025